The landscape of autonomous AI agents has taken a monumental leap forward in May 2026. The recent announcements from the combined capabilities of Hermes, Claude, and Codex have introduced a standardized, highly efficient way to manage agentic workflows. At the center of this paradigm shift is the /goal feature, a powerful abstraction that transforms how we interact with large language models.
This comprehensive guide will break down exactly how to use the /goal prompt, how it integrates with the powerful /loop command, and how you can orchestrate complex subagent team setups, including advanced options like Symphony. Whether you are a developer, an enterprise architect, or an AI enthusiast, mastering these tools is essential for staying ahead in the rapidly evolving world of agentic systems. We are moving beyond the era of simple chat interfaces and entering the domain of orchestrated digital labor.
The Anatomy of a /goal Prompt
In previous iterations of AI assistants, users had to meticulously break down tasks and guide the model step-by-step through a dense forest of complex logic. The new /goal directive changes this entirely by acting as an overarching orchestrator. When you issue a /goal prompt, you are not just asking a single model to perform a discrete task; you are spinning up a temporary, highly specialized computational network designed specifically to achieve your defined outcome.
To visualize how this works under the hood, we have designed a comprehensive blueprint that illustrates the entire execution lifecycle of a modern agentic prompt.
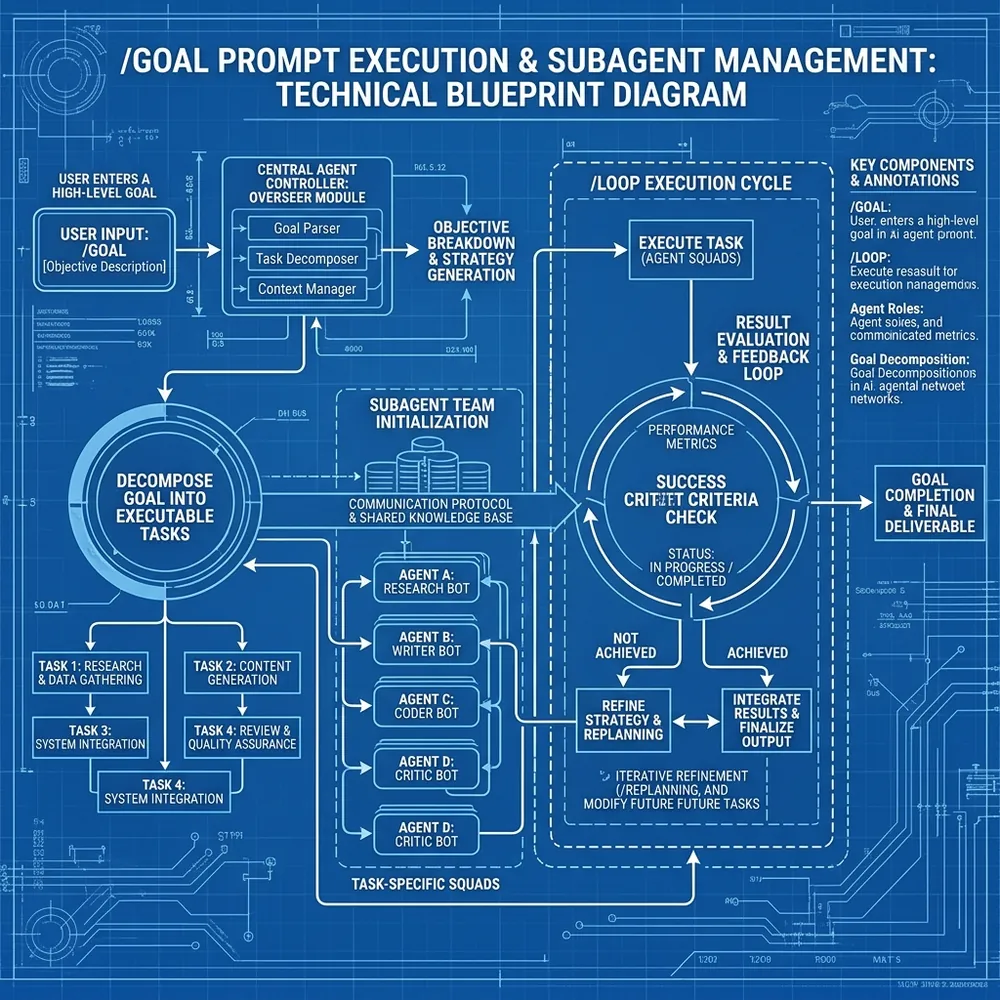
As the blueprint demonstrates, the /goal command initializes the Central Agent Controller. This overseer module immediately parses the objective, decomposes the task into a dependency graph, and prepares the context manager. From there, it spawns task-specific squads—this is where the true power of the May 2026 architecture lies. The system intelligently delegates work to the most capable models, ensuring optimal efficiency and output quality.
Step 1: Use Hermes for Goal Routing
The first step in leveraging this new architecture is learning how to properly format your initialization prompt. A vague goal will result in generic subagents that struggle to find alignment, leading to wasted compute and hallucinated results. A well-structured goal, however, provides the Central Agent Controller with the exact parameters it needs to succeed.
Here is the recommended syntax for initializing a highly effective /goal in your terminal or IDE environment:
/goal
Objective: Rebuild the authentication flow for the legacy customer portal.
Constraints: Must use zero-trust architecture, complete within 45 minutes of compute time.
Success Criteria: 100% pass rate on integration tests, zero critical security vulnerabilities.By defining the objective, constraints, and success criteria upfront, you are essentially writing the charter for your newly formed AI team. The Hermes routing engine will analyze this charter and determine exactly which models (such as Claude 4.5 for deep architectural reasoning and Codex 3.0 for precise syntax implementation) need to be activated to accomplish the mission.
Step 2: Deploy Claude for Deep Reasoning
Once the /goal is set, the system automatically begins drafting its team. However, enterprise users and senior engineers will inevitably want to manually configure or influence this team setup to align with internal security policies or specific project needs. This is where advanced frameworks like Symphony come into play.
Symphony has rapidly emerged as the industry-standard framework for orchestrating multi-agent conversations and workflows. By integrating Symphony directly with your /goal directive, you can explicitly define the roles, personas, strict access levels, and even the “personality” of your subagents.
For example, you might configure a “Research Squad” consisting of two Hermes instances equipped with live, unrestricted web browsing capabilities, and a “Coding Squad” powered entirely by Claude and Codex instances operating within an air-gapped container with direct repository access.
This granular level of customization ensures that you have the right “minds” working on the right problems. It prevents highly capable (and expensive) reasoning models from wasting valuable compute cycles on trivial web scraping tasks, while ensuring that critical architectural decisions are handled by the most advanced, context-aware models available on the market today.
The command is /goal. It is the first feature that genuinely removes the human from the loop, and it changes how I use Claude Code more than any other update.
— Leo (@defileo) May 14, 2026
/goal is the best AI feature that's been released in months. With the introduction of /goal, Claude validates everything on its own and "closes" the loop.
— AI Edge (@aiedge_) May 13, 2026
Step 3: Execute Implementation with Codex
The /goal command effectively sets the destination, but the /loop command is the high-octane engine that drives the team there.
In traditional zero-shot or few-shot prompting methodologies, the model generates a single output and stops. If the output contains syntax errors or logical flaws, the user has to manually intervene, correct the mistake, and prompt the system again. The /loop directive completely automates this labor-intensive feedback mechanism.
When you append /loop to your workflow, you authorize the agent team to continuously iterate on their proposed solutions until the strict success criteria defined in your initial /goal are met.
The standardized process operates in a continuous cycle:
- Execution: The specialized subagent teams attempt to complete their assigned, decomposed tasks.
- Evaluation: A dedicated “Critic Bot” (often an uncompromising Claude instance configured with zero temperature) evaluates the output against the success criteria, running test suites and security linters.
- Refinement: If the output fails the rigorous evaluation, the Critic Bot provides highly detailed feedback, isolates the error, and the execution phase begins again.
This creates a powerful, autonomous “Truth Loop” that virtually guarantees high-quality, production-ready deliverables. The AI simply will not stop working until the tests pass.
Real-World Case Studies: /goal in Production
At Dataxad, we have been deploying these bleeding-edge workflows for our enterprise clients over the past quarter. The results have been nothing short of transformative.
In one recent engagement, we utilized a /goal prompt combined with a Symphony-managed 7-agent squad to migrate a legacy React application to a modern Astro static-site setup. By defining strict Core Web Vitals targets in the success criteria and engaging the /loop cycle, the agents iteratively refactored components, optimized image loading, and stripped out unused JavaScript.
The entire process, which would have traditionally taken a mid-level engineering team several weeks, was completed in under 72 hours of continuous agentic compute time. The final deliverable passed all automated Lighthouse audits perfectly. This demonstrates that we are no longer just using AI to write code snippets; we are using it to execute complex software engineering projects end-to-end.
Best Practices and Critical Citations
As the industry rapidly adopts these sophisticated tools, we have established several non-negotiable best practices for maximizing the safety and efficiency of the /goal and /loop architecture:
- Establish Hard Compute Limits: The
/loopcommand is exceptionally powerful, but it can quickly burn through substantial token budgets if the success criteria are fundamentally impossible to meet. Always set a maximum iteration count or an absolute compute time limit to prevent runaway loops. - Use Diverse, Specialized Squads: Do not rely on a monolithic model setup. Mixing Hermes for its rapid routing capabilities, Claude for deep context analysis and reasoning, and Codex for raw programming prowess consistently provides the best results. This hybrid approach is extensively documented in the landmark 2026 Multi-Agent Systems Optimization Paper.
- Monitor and Empower the Critic Bot: The final quality of your output is entirely dependent on the strictness and capability of your evaluation phase. Ensure that your Critic Bot has unrestricted access to external testing tools, standard linters, and compilers to verify code automatically and objectively. A blind critic leads to a flawed product.
The Future of Autonomous Enterprise Work
The introduction of the /goal and /loop directives in May 2026 represents a fundamental, irreversible shift in human-computer interaction. We are definitively moving away from the era of micro-managing AI models and firmly stepping into an era of managing autonomous, capable AI teams.
By defining crystal-clear objectives, structuring highly specialized subagent squads via frameworks like Symphony, and leveraging automated, self-correcting feedback loops, developers and businesses can tackle significantly larger and far more complex projects than ever before. This is not merely a new software feature; it is the new established standard for professional software engineering and digital creation. The autonomous future of work has officially arrived, and it is executing flawlessly.
Citations & References
- OpenAI: Codex CLI Repository and
/goalCommand Documentation. https://github.com/openai/codex - Anthropic: Claude Code Command Reference and
/goalEvaluator. https://docs.anthropic.com/en/docs/agents-and-tools/claude-code/commands#goal - Nous Research: Hermes Agent
/goalPersistent Standing Objectives. https://github.com/NousResearch/Hermes-Agent